ランダムフォレスト
ランダムフォレストとは、複数の決定木を組み合わせたアンサンブル学習法の一つです。多数の決定木を用いて分類や回帰、クラスタリングを行うことができます。決定木の過学習しやすいという問題を解決したより精度が高い手法と言われています。
手法について
ランダムフォレストは教師あり学習の一つであり、決定木の持つ過学習しやすいという問題を解決するアンサンブル学習法です。
ランダムに抽出したデータを用いて決定木を作成するといった工程を繰り返し、作成された複数の決定木を集約することで最終的な分析結果を決定する手法です。
ランダムにデータを抽出することで、決定木のデメリットとして挙げられている過学習が抑制され、また各決定木の精度は高くないが複数の決定木を組み合わせることで高精度のモデルとなります。
手順・式
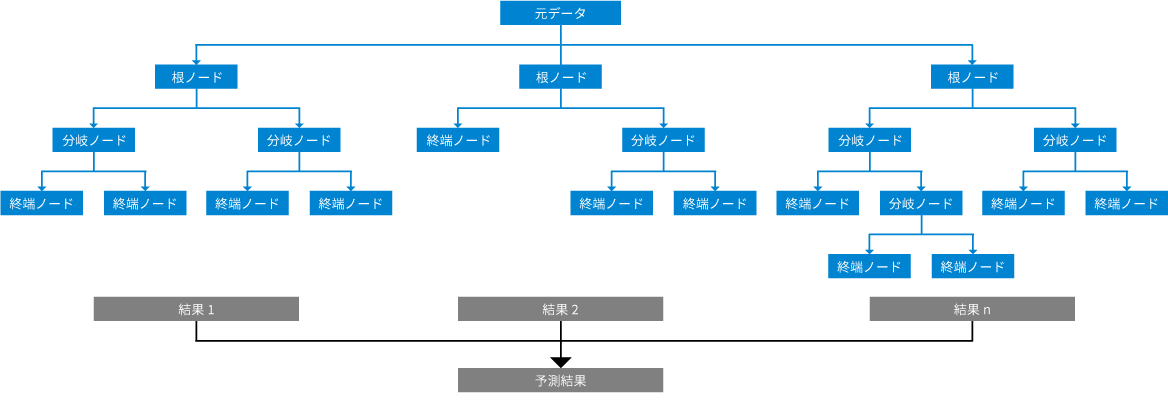
ランダムフォレスト分析では、決定木分析と同様に目的変数と複数の特徴量を用意する必要があります。ランダムフォレスト分析の作成手順は以下の通りです。
(1)ランダムデータの抽出
用意したデータセットからランダムにサンプルを選択し、新たなデータセットを作成します。
(2)ランダムな特徴量を作成
(1)のデータセットから特徴量をランダムに選択し、新しい特徴量セットを作成します。
(3)決定木の作成
(1)のデータセットと(2)の特徴量セットを使用し、決定木を作成します。
(4)複数の決定木を作成
(1)~(3)までの工程を複数回行い、複数の決定木を作成します。
(5)最終的な予測値の算出
作成した複数の決定木の予測値をもとに最終的な予測値を算出します。回帰や予測問題では平均値を、分類や判別問題では多数決を取ることが多いです。
メリット・デメリット
【メリット】
①過学習になりにくい
ランダムに抽出したデータで作成した決定木のアンサンブル学習を行うことで、分散を抑え過学習を防ぐことができます。
②説明変数の重要度を測定可能
各説明変数が分類にどの程度寄与しているか、重要度が高い説明変数かを評価することができます。
【デメリット】
①予測結果の説明が難しい
複数の決定木をもとに予測値が算出されるため、結果の解釈が難しい場合があります。
②処理に時間がかかる
多数の決定木を作成するため計算量が多く、また大量なデータを処理する場合は高速な計算が行える環境が必要となります。
関連分析技術
ロジスティック回帰 リッジ回帰 重回帰分析 決定木 XGBoost LightGBM 勾配ブースティング決定木
関連サービス
当社ではこのような機械学習・分析技術を活用した予測モデル、AIモデルの提供を行っています。
・無担保ローンニーズモデル
・メール配信ターゲット抽出モデル構築
・商品レコメンドモデル構築
・商品の需要予測
もっと見る
採用情報
機械学習・分析技術で顧客の課題解決に貢献するデータサイエンティストとして働いてみませんか。
ぜひ採用ページもご覧ください。
