Tacotron2+WaveGlow を動かす(音声合成)【前編】
モデルが古くて動かせないケースの解決方法
音声認識と生成系AI
昨今、音声認識技術は、チャットポット、文字起こし等で広く実用化され始めています。
一方で、今はまさに生成系AIブームで、一般用途ではゲーミング用途にとどまらず、一部のマニア界隈ではStable Diffusion(画像生成)を動かすために高価なGPU(十分なVRAM容量が必要)が必要で、マイニングブームが下火となった現在でも、ニーズが衰えることなく、円安状況も相まって価格は高値安定といった状況です。(ChatGPTも自然言語系AIとしては、生成系AIに含まれます)
Tacotron2+WaveGlow
音声データにおける生成系AIといえば、音声合成があります。著名なものに、今回取り上げる、Tacotron2+WaveGlowがあります。
(論文:https://arxiv.org/abs/1712.05884)
このモデルでは同一の話者が吹き込んだデータを用意し、モデル学習をすれば、その人物の特徴をモデルに取り込み、打ち込んだテキストから、本人そっくりの音声を生成させることができます。tacotronのサイトには、The LJ Speech Datasetで学習したデモが用意されています。
このモデルの良いところは、Tacotron2モデル でテキストからメルスペクトログラムを作成し、それを基にしてWaveGlowモデルで音声合成を行うという、2段階の処理になっているところだと思います。(下図 )
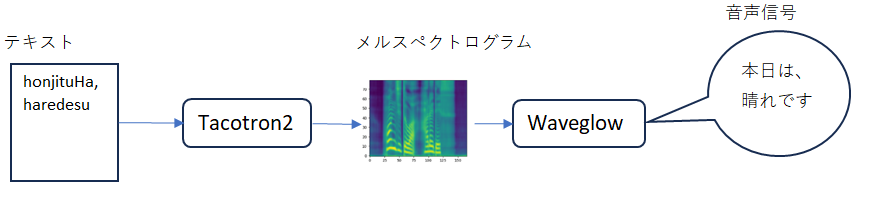
メルスペクトログラム
メルスペクトログラムは一言で言うならば、時間、周波数および信号強度からなる3次元データで、音声認識・音声合成を学ぶ者は必ず通る道であり、いってみれば基本中の基本といったデータで、プロットすることによって簡単に視覚化できます。
音声データからメルスペクトログラムを作るのはPythonで簡単に行えます。言ってみればモデルの動きを視覚的にとらえやすい。
最近の性能が高いといわれているE2E(End-to-end)型のモデルでは、このメルスペクトログラムを生成する工程をバイパスする構成になり、モデルがブラックボックス化します。個人的には、Tacotron2は、途中結果を視覚化できるという点で、一度は動かしておきたいモデルだと思います。
次回
今回はTacotron2の概要についてお伝えしました。次回は実際にTacotron2を動かす際の実装方法について解説します。
関連記事
・Tacotron2+WaveGlow を動かす(音声合成)【後編】
当社について
日々最先端の機械学習・分析技術の研究を行い、それらを活用した予測モデル・AIモデルの提供を行っています。
・テキスト情報を用いた分類モデル構築
・メール配信ターゲット抽出モデル構築
・商品レコメンドモデル構築
もっと見る
