動画解析による事故検知AIのモデル構築と実装に向けた課題
1.はじめに
近年では自動車業界において、自動運転や安全運転システムなどの開発にAI技術が積極的に活用されています。弊社ではカーナビゲーションやドライブレコーダーなどのカーエレクトロニクス製品を手がけるA社様と共同開発を行い、動画認識モデルにより大量のドライブレコーダー映像を事故動画と事故が発生していない動画(以下、非事故動画)に分類する事故検知モデルの開発を行いました。今回開発したモデルにより以前は目検で長時間かかっていた動画の分類や事故シーンの特定について、作業時間の短縮につなげることができるようになりました。
なお、本記事では、Google が公開するViViTのベースモデル( Hugging Face:google/vivit-b-16×2、MIT License 2.0)を使用し、独自データセットを用いてファインチューニングを行いました。当ページでは、学習により得られた評価指標などの結果のみを公表しています。元データ(動画・画像など)はライセンスおよび権利保護のため公開していません。
※Google および Hugging Face は、それぞれ Google LLC、Hugging Face, Inc. の登録商標です。
図表1 事故検知モデルによる動画分類のイメージ
※フリー素材を活用しFEGが作成
2.動画認識モデルとは
動画認識モデルとは、データを分析して動画内で何が行われているか内容を理解するためのAIモデルです。画像認識モデルの発展形であり、画像内の情報に加えてフレーム間の変化も考慮することで、画像内に映っている物体の動きやイベントを認識できます。動画認識モデルの活用例としては以下が挙げられます。
・アクション認識:主に人間の行動(食べる、走る、座るなど)を認識。
・イベント検出:特定の出来事(スポーツの得点シーンなど)を検出。
・オブジェクト追跡:動画内で同じ物体(車両など)を追跡。
・動画キャプション生成:動画の内容を説明し、キャプションを生成。
今回はGoogle社が2021年に発表した動画認識モデルViViTをドライブレコーダー映像を用いて再学習させることで事故検知モデルの開発を行いました。ViViTでは内部のアルゴリズムに自然言語分野から派生したTransformerが採用されており、発表当時、複数の主要な動画分類のベンチマークにおいてSoTAを達成しました。Kinetics-400データセットで追加学習されたViViTモデルも公開されており、入力した数秒の動画から人物の動作を予測し分類することが可能です。今回はViViTベースモデルに対して再学習を実施することで自動車の衝突などのイベント検出の推論も可能と考え、モデル実装を行いました。
※ViViT:Video Vision Transformer:動画を Transformer で理解するための深層学習モデル
※Transformer:「系列データの“どこが重要か”を自分で判断して学習するモデル」で深層学習アーキテクチャの名称
※SoTA:State of the Art:現時点での最高水準・最先端を意味する
※Kinetics-400:DeepMindが提供する動画分類やアクション認識のための代表的な大規模データセット
※DeepMind は Google LLC の登録商標です。
図表2 ViViTモデルのアーキテクチャ図
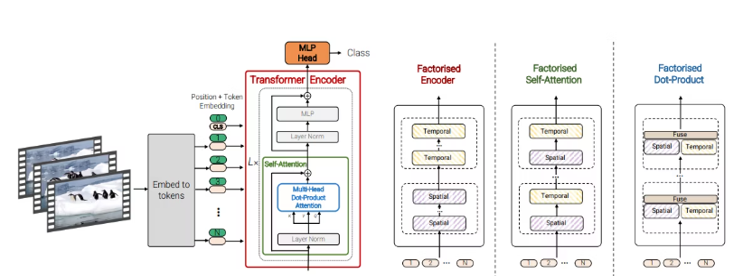
※出所:https://arxiv.org/abs/2103.15691
3.モデルの実装
3章ではモデルの再学習について説明します。今回は事前学習モデルを用いてファインチューニングを実施しました。ファインチューニングでは、事前学習済みモデルのパラメータを新しいデータセットで追加学習することで、特定のタスクに適したモデルへ適応させることが可能です。今回使用したViViTのベースモデルはhuggingfaceにて公開されているものを使用しました(https://huggingface.co/google/vivit-b-16×2)。
まず初めにデータの準備です。ドライブレコーダーの映像に対してアノテーションを実施し、事故動画(車両事故、自転車事故、人身事故、物損事故)と非事故動画のカテゴリに分類します。データは事故動画約150本、非事故動画約500本を6:2:2の割合で学習、評価、テスト用に分割して使用しました。再学習により非事故、車両事故、自転車事故、人身事故、物損事故の5カテゴリをモデルが正しく分類できるようにするのが目標となります。また、事故シーンが概ね4~5秒程度に収まるため、学習に使用する動画はいずれも5秒程度に加工しています。
以下の図では再学習させたモデルを使って与えられた動画をどのように事故動画と推定するかの手順を記載しています。手順は大まかに分けて2つになります(図表3)。
①動画を4秒単位で非事故/事故(車両/自転車/人身/物損)か予測←事故検知モデルにて推定
②予測結果のうち事故フラグのしきい値が80%以上のものが含まれている場合、事故動画と判定、そうでない場合に非事故と判定
※アノテーション:データに対してラベルを付与する作業のことであり、ここでは各動画を車両事故、非事故動画などに振り分けることを指します。
図表3 事故分類ロジックのイメージ図
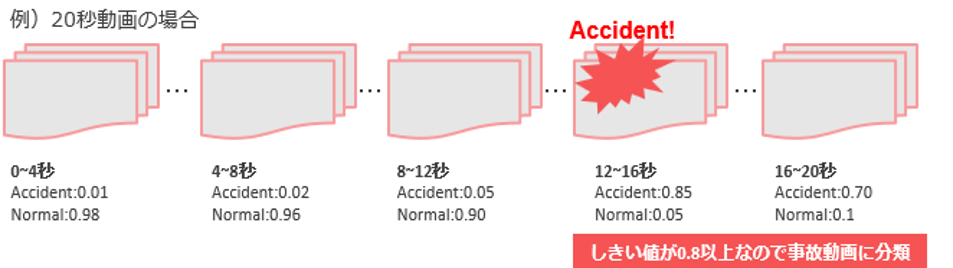
※フリー素材を活用しFEGが作成
4.精度評価と今後の課題について
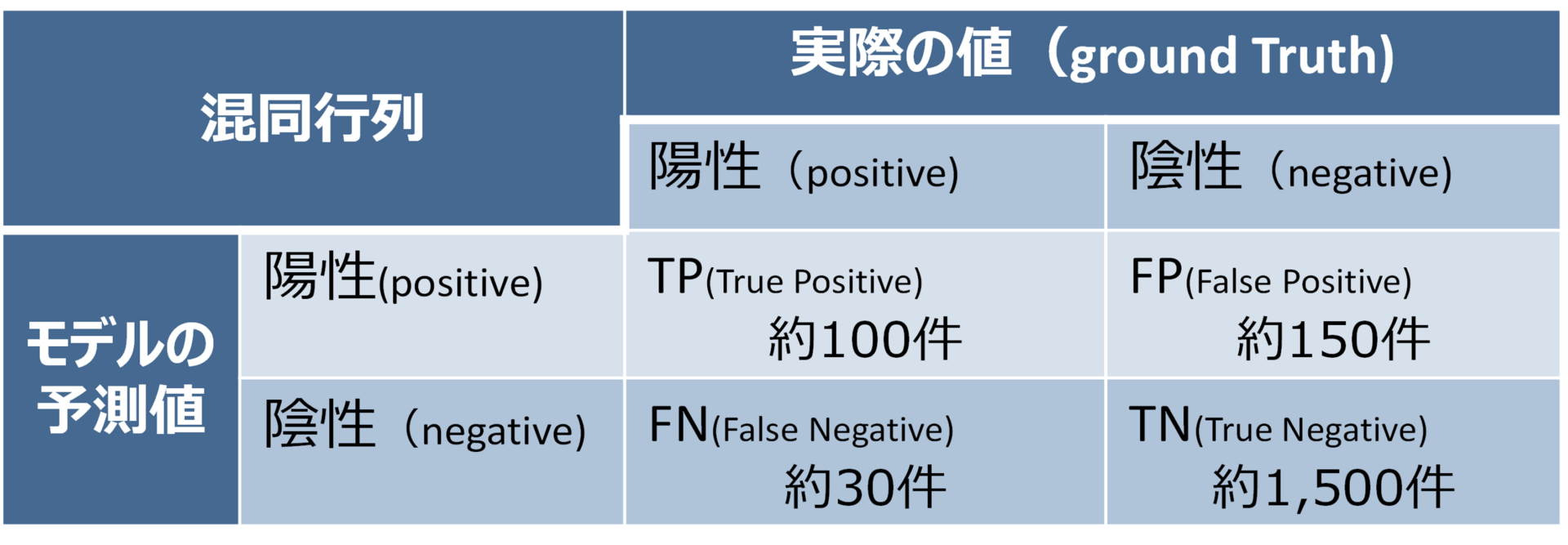
ドライブレコーダーの動画約2,000件を用いて精度検証を行いました。精度指標は以下の通りです。
・適合率(Precision):38%
・再現率(Recall):78%
・F1スコア:51%
・正解率:90%
| ※適合率(Presision:モデルが事故と予測した動画のうち、実際に事故であった割合) | : TP÷(TP+FP) |
| ※再現率(Recall:実際の事故動画のうち、モデルが事故と予測できた割合) | : TP÷(TP+FN) |
| ※F1スコア(適合率と再現率の調和平均) | : 2×(適合率×再現率)÷(適合率+再現率) |
| ※正解率(全体のうちモデルが正しく予測できた割合) | : (TP+TN)÷(TP+FP+FN+TN) |
図表4 精度評価指標のまとめ
※検証結果をもとにFEGが作成
正解率は90%超と高かったですが、閾値を調整しても事故/非事故が判定できない動画が一部存在するモデルとなりました。
誤検知に対する定性的な印象は以下の通りです。
・FN(実際は事故、予測は非事故):縁石やガードレールへの接触、自転車との軽微な接触、映像だけでは判断が難しい後進時の事故や自車側部への接触など、判別が難しいものが多かったです。それらのケースに該当する学習データを増やして再学習することで改善する可能性が考えられます。
・FP(実際は非事故、予測は事故):振動や右左折などのみで事故と反応しているケースがあり、事故のパターンによっては再学習しても改善しない可能性があります。この場合は別途物体検知モデルと組み合わせて、車両を検知した場合のみ車両事故とするなど、実用上は工夫が必要と考えられます。
モデルの再学習を工夫することで改善できそうな点もありますが、動画分類モデルのみでなく、物体検知モデルや音による判定など別のAI技術による改善も検討できそうです。
次回
次回は事故映像に対して、事故の原因(自車追突/他車追突)を分類するAIモデルの開発内容について執筆予定です。今回は動画内に事故シーンがあるかどうかを判定するAIモデルでしたが、より踏み込んで、動画データを用いたAIモデルで自動車事故における自責・他責の判定が可能か検討・調査します。
当社について
日々最先端の機械学習・分析技術の研究を行い、それらを活用した予測モデル・AIモデルの提供をおこなっています。
・テキスト情報を用いた分類モデル構築
・メール配信ターゲット抽出モデル構築
・商品レコメンドモデル構築
もっと見る
サービス紹介ページをご覧いただき、お気軽にお問い合わせください。
